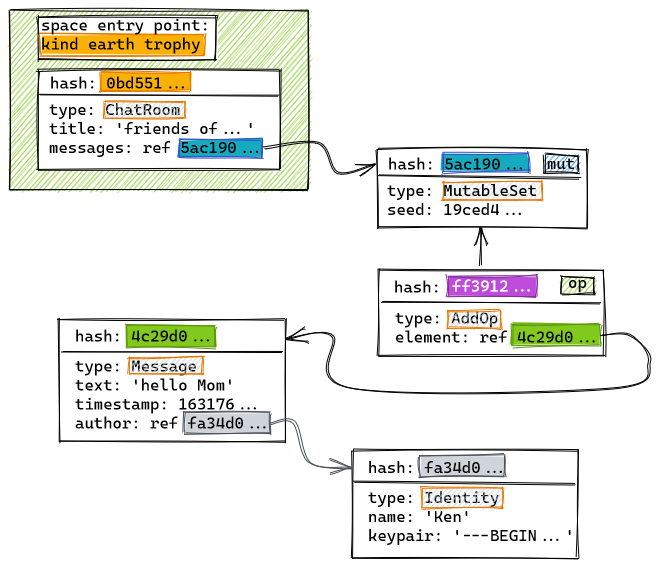
In the Hyper Hyper Space data model, each object created by the application is mapped into a JSON literal and then hashed. The resulting <hash, literal> pair is then appended to the application's DAG. While primitive data types are mapped to JSON verbatim, refrences to other objects are transformed into hash-based references that form arcs in the graph:
let m = new Message();
m.text = 'hello Mom'
m.timestamp = Date.now();
m.author = ken;
store.save(m);
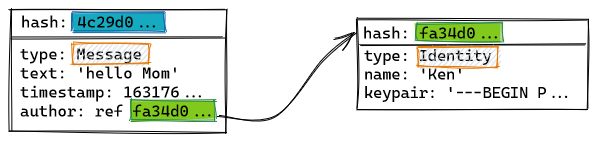
When one an object is replicated from one peer to another, its references are identified and sent automatically. All objects are typed, and each application informs the set of datatypes that it will accept. Types come equipped with a validation function that will be used by the replication layer to accept or reject received additions to the local copy of the state-DAG.
Mutability
Mutable objects are represented using operation-based datatypes. A mutable object is appended to the DAG in a defined initial state, and later changes are represented as mutation objects that reference it. Since when replicating a mutable object all the mutations must be replicated as well, both are labelled as such in the DAG.
In the following example, the Message object created above is inserted into a MutableSet:
...
let s = new MutableSet();
s.add(m);
store.save(s);
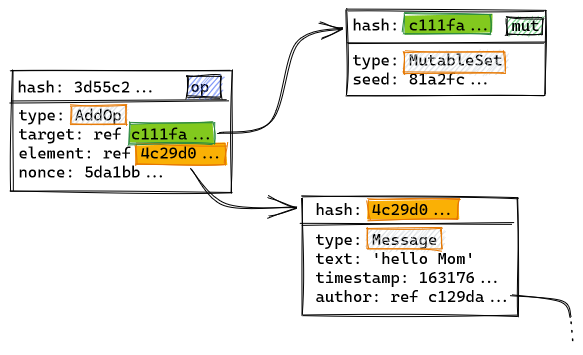
The created MutableSet object, that initially represents an empty set, includes a random seed in its JSON-like representation. This makes its hash c111fa… unique. Otherwise, new MutableSet() would always return a reference to the same empty set. As operations adding and removing elements from the set are later appended to the DAG, the hash of the set object itself remains constant and can be safely used to create references in the rest of the model. Operations will usually also include a random nonce, like the AddOp above, to make them unique.
Operations also include a prev field that references the most recent mutations that have been accepted to the local DAG. In the following example, a series of operations on an observed-remove set have been executed serially on a peer. The vertical arrows indicate the prev relationship, while the DeleteOp object has an additional blue arrow pointing to the additions that are being cancelled:
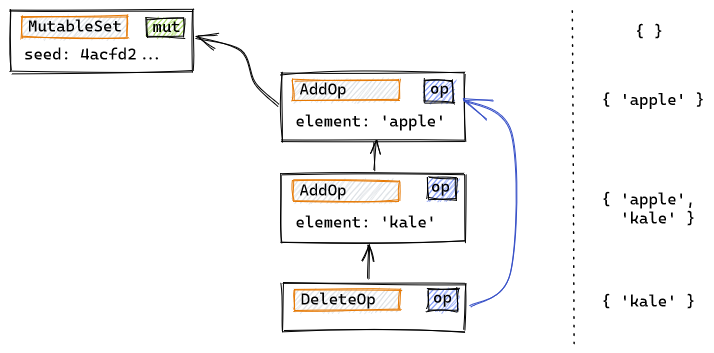
When an object is modified concurrently by several peers, prev doesn't guarantee that all operations will reach peers in the same order. Mutable datatypes need to ensure convergence, usually by employing commutative operations, following the techniques developed for CRDTs. Below we see how two peers, Ken and Mary, have concurrently added some elements to a set. Later on a synchronization occurs, and finally Ken adds a last element:
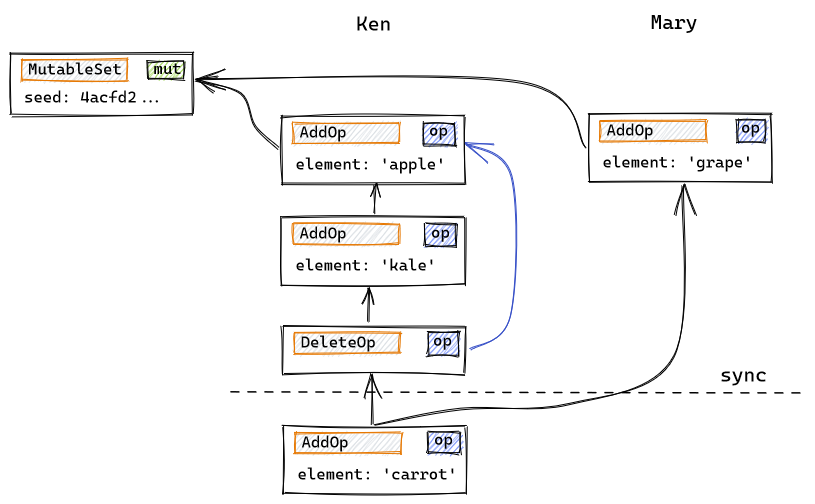
After the synchronization, Ken's local version of the DAG includes Mary's update, and that is reflected by his next operation having two predecessors (the last of Ken's previous updates, and Mary's).
When comparing the state of a mutable object in two different replicas, the prev relationship allows peers to quickly determine if both replicas have the same set of operations, if one replica supersedes the other, or if they are in divergent states, usually within a single round-trip.
Pseudo-finality
Since peers may work over intermittent connections or while being offline, new mutation operations may appear with arbitrary large delays, and therefore arbitrarily far away from the current state in terms of the hops defined by the prev relationship described above. This prevents applications from enforcing a state change that is final across all peers.
For example, if the application needs some form of user capability system, and capabilities can be granted and revoked, a revoked capability may still be used if, either because of propagation delays or malicious intentions, new operations are inserted far back in the object's history (when the capability was still valid). To preserve operation commutativity, these untimely capability uses would need to be accepted, hence preventing the application from truly enforcing capability revocation.
This problem is mitigated by introducing causal relationships between operations, enabling application designers to indicate that an operation is causally dependent on the validity of another. The example below uses the class CapabilitySet from Hyper Hyper Space's standard library. It is similar to MutableSet, but instead of inserting and deleting elements, capabilities are granted, used and revoked. Causal relationships are shown in green:
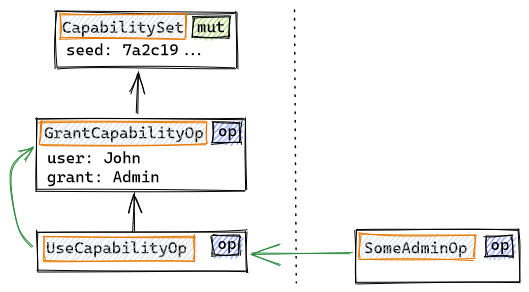
In the DAG fragment shown above, John was granted Admin rights and used them to perform SomeAdminOp, which is a mutation on another object. The green causal arrows show that SomeAdminOp is dependent on a UseCapabilityOp, which itself depends on the GrantCapabilityOp that made John an admin.
To revoke Admin rights, we will use a RevokeCapabilityOp, which will be a special InvalidateAfter type of operation.
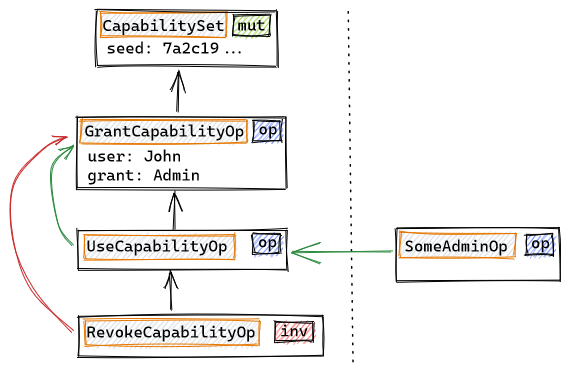
The role of InvalidateAfter-type operations is preventing any further causal consequences of the invalidated operation after that point in history (the partial order defined by the prev relationship, indicated by the black arrows). Note that all the UseCapabilityOp operations are inside the history graph for the CapabilitySet object, independently of the object in wich the capability is effectively being used (indicated by the green causal references). If new operations with causal dependencies on the invalidated operation appear outside of the history fragment that lays before the InvalidateAfter operation (RevokeCapabilityOp in our example), they will be automatically undone by the local store. This will be done by automatically appending an special UndoOp to the graph:
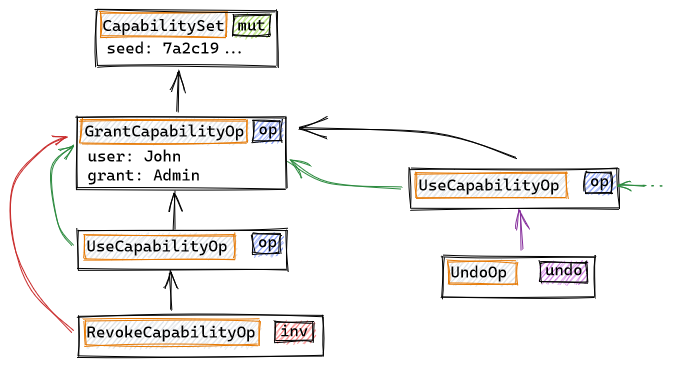
Undos are created by the local store whenever an operation is causally dependent on another that has been invalidated at that point in history, and are cascaded automatically (in the example above, the undo will be cascaded to any operations that depend on that use of the Admin capability). Sometimes an undone op needs to be redone (because the InvalidateAfter op that caused it had its own causal dependencies, that were undone as well). This is also done automatically by the store.
While the tools just described do not provide a real finality solution, because InvalidateAfter-type ops are still prone to causing problems when delayed or purposefully ill-constructed, the combination of InvalidateAfter and Undo gives application designers a way to mitigate its consequences by limiting by construction which patological cases may actually arise.
Synchronization
During normal operation, applications operate on the local store, that holds a copy of the state-DAG. In order to mantain its contents in sync with other peers, the application configures Hyper Hyper Space's mesh network and indicates which mutable objects (that are specially labelled in the DAG) need to be kept synchronized.
Transport Layer & Signalling
Hyper Hyper Space uses WebRTC and WebSockets as its transport protocols.
WebRTC browser-to-browser connections cannot be established without a signalling server, that helps both ends negotiate connection parameters. This set-up has been adapted to work in a distributed setting by allowing each peer to have his own signalling server. The web client keeps a WebSocket connection permantly open to its signalling server, that will relay any connection establishment messages it receives back to the browser.
To build the bi-directional channel needed to establish a WebRTC connection, a web client will open a second WebSocket to the signalling server used by the destination peer, that must be known beforehand, like this:
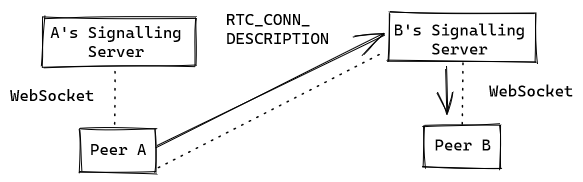
If it wants to accept the connection, Peer B will also connect to Peer A's signalling server to be able to send his own connection establishment messages back to Peer A. Once the WebRTC is ready, both peers can drop the WebSocket connection to the other's signalling server:
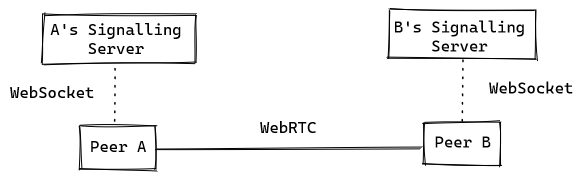
The connection to the other peer's signalling server may be reopened if further connection management messages must be sent (e.g. if a peer is on a cellullar network and its IP address is changing).
If the application uses a significant amount of data, it may selectively activate and deactivate synchronization of objects as they are needed.
Signalling servers need not be exclusive to a single peer. Thery are used very lightly and can be safely shared. In the future, signalling servers may use a DHT to free peers from having to know the signalling server another peer is using in order to establish a connection.
Peers running in native environments may use WebSockets directly, if they are available, instead of WebRTC connections.
Mesh Network
Peers in the network form application-defined groups over which mutable objects are synchronized. The method for obtaining peers is also application defined: it may be a peer set kept in the DAG-state of the app, an external source (a torrent file or similar) and finally the signalling servers support piggybacking messages to obtain a list of bootstrapping peers. Each peer connects to N random peers in the group. N should be chosen by the application to ensure with high probability that the resulting network overlay topology inculdes a spanning tree.
Gossip & Synchronization
Each peer group implements an epidemic gossip protocol where each peer informs which objects they are synchronizing, and the state they are in. Object state is determined by taking the set of operations that are maximal in the operation history, using the prev partial order.
Whenever gossip reveals an object to be in two different states, a syncrhonization is performed. Sync starts by peers requesting the headers of the operation history they are missing, and then using that information to request the actual operations they need to fetch. The sync protocol is optimized to reduce round trips. It attempts to deduce which operations will be requested, and starts streaming them back as soon as it can infer they are needed. The receiving peer can send further messages to correct what he is getting.